
【AWS】什么是Amazon SageMaker

【AWS】什么是Amazon SageMaker
Amazon SageMaker 是一项完全托管的机器学习 (ML) 服务,它为数据科学家和开发人员提供了快速构建、训练和部署任何规模的机器学习模型的能力。SageMaker 旨在消除机器学习过程中各个步骤的繁重工作,让您能够更轻松、更高效地开发高质量的 ML 模型。
您可以将 Amazon SageMaker 想象成一个**“云中的端到端机器学习平台”**。它提供了从数据准备、模型构建、训练、调优到部署和监控的整套工具和基础设施,覆盖了机器学习的整个生命周期。
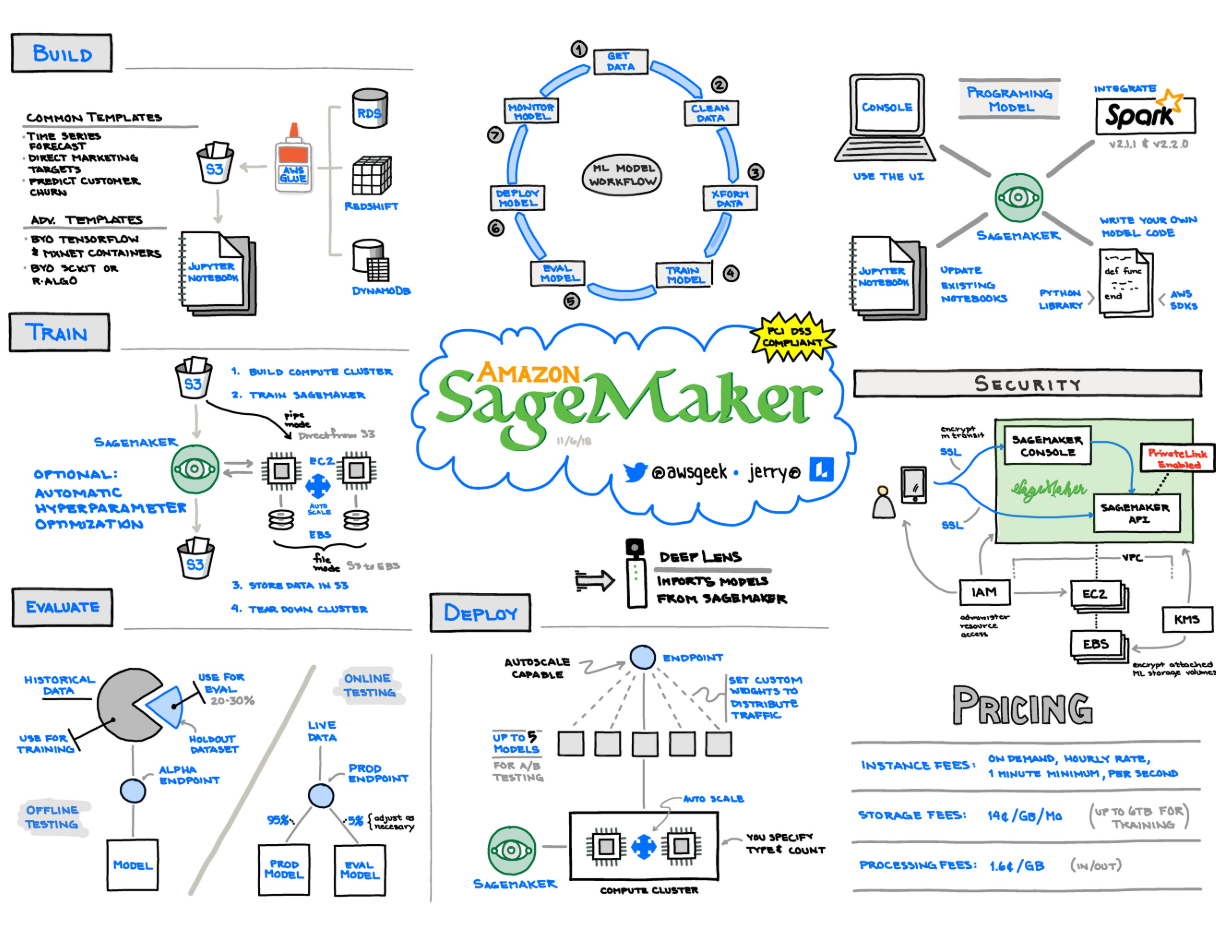
Amazon SageMaker 的核心功能和优势
SageMaker 旨在简化机器学习工作流,提高开发效率和模型性能。
- 集成式开发环境 (IDE):Amazon SageMaker Studio: 一个完全托管的 Web IDE,提供统一的界面来执行 ML 工作流中的所有步骤。它集成了 JupyterLab、Code Editor (基于 Visual Studio Code) 和 RStudio,方便数据科学家和开发人员进行数据探索、模型构建、训练和调试。统一体验: 在一个环境中即可使用所有数据和工具进行分析和 AI 开发,包括数据探索、生成式 AI、数据处理和 SQL 分析。
- 数据准备和特征工程:SageMaker Data Wrangler: 简化数据聚合和准备过程,通过可视化界面快速清理、转换和组合数据,为 ML 模型做好准备。SageMaker Processing: 提供完全托管的计算环境,用于大规模运行数据处理、特征工程和模型评估工作负载。
- 模型构建和训练:托管式 Jupyter 笔记本: 提供预装了常用 ML 框架(如 TensorFlow、PyTorch、MXNet)和库的 Jupyter 笔记本实例,方便快速开始。内置算法和模型: 提供一系列高性能、可扩展的内置 ML 算法,针对速度、规模和准确性进行了优化,可以在 PB 级数据集上执行训练。自动机器学习 (AutoML) - SageMaker Autopilot: 自动探索数据、选择最佳算法、训练和调优模型,并生成最佳模型,即使没有 ML 经验的用户也能快速构建模型。分布式训练: 支持在多个 GPU 或实例上进行分布式训练,加速大型模型的训练过程。超参数调优 (Hyperparameter Tuning): 自动调整模型的超参数,以找到最佳模型版本,提高模型精度。
- 模型部署和推理:实时推理: 训练完成后,可以将模型部署到 SageMaker 托管的持久端点上,以实时获取预测结果。SageMaker 会自动管理底层基础设施的扩展和高可用性。批量转换 (Batch Transform): 适用于离线获取整个数据集的预测结果,无需部署实时端点。多模型端点 (Multi-Model Endpoints): 在单个端点上托管和部署数百甚至数千个模型,降低推理成本。无服务器推理 (Serverless Inference): 允许您部署机器学习模型,而无需配置或管理底层基础设施,并根据实际使用量自动扩展。
- 模型监控和管理 (MLOps):SageMaker Pipelines: 用于构建、管理和自动化端到端 ML 工作流,实现持续集成和持续交付 (CI/CD)。SageMaker Model Monitor: 持续监控生产环境中部署的 ML 模型,检测数据漂移、模型性能下降等问题。SageMaker Model Registry: 集中存储和管理模型构件和元数据,方便模型版本控制和部署。SageMaker Clarify: 帮助检测 ML 模型中的偏差并解释模型预测,提高模型的公平性和透明度。
- 生成式 AI 和基础模型 (Foundation Models):SageMaker JumpStart: 提供数百种常用公开模型和预构建解决方案,用于快速构建生成式 AI 应用程序,包括访问来自顶级模型提供商的基础模型。模型微调和评估: 支持对基础模型进行微调,并根据精度、稳健性、毒性等指标快速评估、比较和选择最佳基础模型。
- 成本效益:您只需为实际使用的资源量付费,没有前期投资。提供多种优化选项,如 Spot 实例、自动停止不活跃的笔记本等,以降低成本。
Amazon SageMaker 的工作原理
SageMaker 简化了机器学习的每个阶段,通常的工作流程如下:
- 数据准备:数据存储: 将原始数据存储在 Amazon S3 中。数据探索和分析: 使用 SageMaker Studio 中的 Jupyter 笔记本进行数据探索和可视化。数据处理: 使用 SageMaker Data Wrangler 或 SageMaker Processing 对数据进行清洗、转换、特征工程和标注。
- 模型构建:选择算法: 可以使用 SageMaker 内置的算法,也可以使用流行的 ML 框架(如 TensorFlow、PyTorch)编写自定义代码,或者利用 SageMaker JumpStart 中的预训练模型。开发环境: 在 SageMaker Studio 或托管式笔记本中编写和测试模型代码。
- 模型训练:启动训练作业: 配置训练作业,指定输入数据位置、算法、实例类型和数量等。自动管理: SageMaker 会自动预置和管理底层计算资源(如 EC2 实例),进行分布式训练和超参数调优。模型构件: 训练完成后,模型构件(训练好的模型文件)会自动存储到 Amazon S3。
- 模型部署:创建推理端点: 将训练好的模型部署为实时推理端点,SageMaker 会自动管理端点的扩展和高可用性。批量转换: 对于离线预测,可以使用批量转换功能。
- 模型监控和管理:持续监控: 使用 SageMaker Model Monitor 持续监控生产模型的性能和数据质量。工作流自动化: 使用 SageMaker Pipelines 自动化整个 ML 工作流,包括数据准备、训练、部署和监控。模型注册: 将模型注册到 SageMaker Model Registry,进行版本控制和管理。
Amazon SageMaker 的典型用例
- 预测性分析:欺诈检测: 分析交易数据以识别潜在的欺诈行为。信用评分: 评估客户的信用风险。需求预测: 预测产品需求、库存水平。设备故障预测: 基于传感器数据预测设备何时可能发生故障(预测性维护)。
- 个性化和推荐系统:产品推荐: 根据用户行为和偏好提供个性化的产品推荐。内容推荐: 为用户推荐电影、音乐或文章。
- 计算机视觉:图像识别和分类: 识别图像中的物体、场景或人脸。缺陷检测: 在制造业中自动检测产品缺陷。
- 自然语言处理 (NLP):情感分析: 分析文本数据(如客户评论)中的情感。文本分类: 对文本进行分类(如垃圾邮件检测)。聊天机器人和虚拟助手: 构建智能对话系统。
- 生成式 AI 应用程序:内容生成: 生成文本、图像、代码等。智能客服: 构建能够理解和响应复杂查询的客服系统。药物发现和材料科学: 加速新分子和材料的发现。
- 各行业应用: 医疗保健(患者数据分析、个性化治疗)、金融(金融欺诈检测、风险评估)、零售(库存优化、个性化客户体验、定价策略优化)等。
总结来说,Amazon SageMaker 是一项全面且强大的机器学习平台,它通过提供涵盖 ML 生命周期的所有阶段的工具和完全托管的服务,极大地降低了构建、训练和部署 ML 模型的复杂性,帮助各种规模的企业更快、更轻松地将 AI/ML 创新投入生产。
关注
收藏
赞
踩