
【AWS】什么是Amazon Athena(无服务器交互式查询服务)

【AWS】什么是Amazon Athena(无服务器交互式查询服务)
Amazon Athena 是一项交互式查询服务,它允许您使用标准 SQL 轻松分析 Amazon S3 中的数据。
您可以将 Amazon Athena 想象成一个**“云中的即时数据分析师”**。它使得数据分析变得简单,您只需指向 Amazon S3 中的数据,定义一个模式(如果数据没有结构),然后就可以开始使用标准 SQL 查询数据,而无需预置或管理任何基础设施。
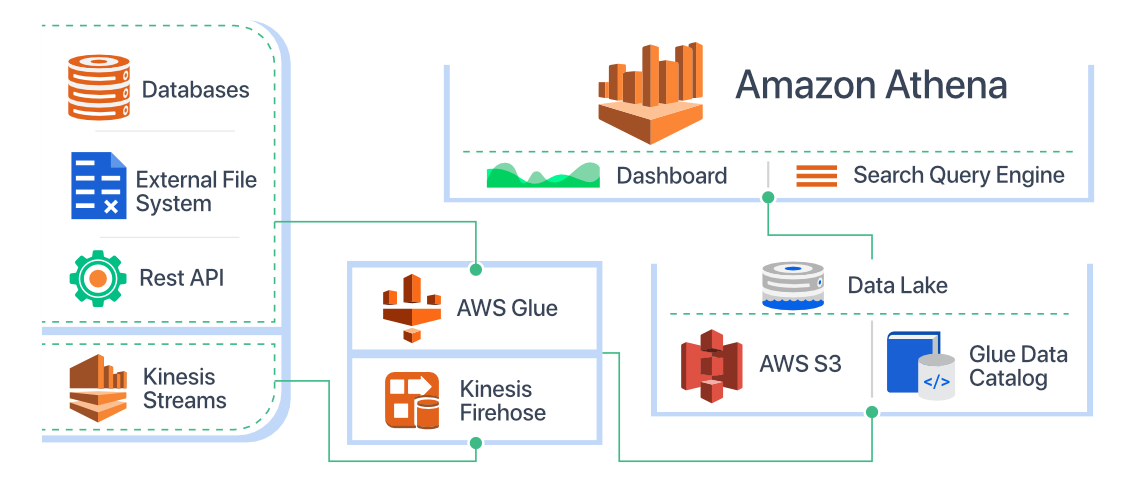
Amazon Athena 的核心功能和优势
Athena 旨在提供一种灵活、经济且易于使用的方式来查询大规模数据。
- 无服务器和按查询付费:Athena 是一项完全托管的无服务器服务。您无需管理任何服务器、数据仓库或集群。您只需为运行的查询付费。根据扫描的数据量计费,没有前期费用或最低费用。这使得它在处理偶发或探索性查询时非常经济高效。
- 使用标准 SQL:您可以使用熟悉的标准 SQL 语法来查询数据,这大大降低了学习曲线,并允许您利用现有的 SQL 技能。支持 ANSI SQL,并兼容 PrestoDB。
- 直接查询 Amazon S3 中的数据:Athena 可以直接查询存储在 Amazon S3 中的数据,支持多种数据格式,包括 CSV、JSON、ORC、Parquet、Avro 和 TextFile。这使得您可以将数据存储在成本效益高的 S3 中,并按需进行查询,而无需将数据加载到单独的数据仓库中。
- 与 AWS 生态系统深度集成:Amazon S3: 作为主要的数据湖存储层。AWS Glue Data Catalog: Athena 使用 Glue Data Catalog 来存储和管理数据的元数据(表定义、模式信息)。Glue Data Catalog 是一项托管的元数据存储服务,可以自动发现 S3 中的数据模式。Amazon QuickSight: 可以将 Athena 作为数据源,用于创建交互式仪表板和可视化。Amazon CloudWatch: 用于监控 Athena 查询的性能和使用情况。AWS Lake Formation: 用于对数据湖中的数据进行精细的访问控制和安全管理。
- 高性能和可扩展性:Athena 能够并行执行查询,处理大规模数据集,并提供快速的查询结果。它可以根据查询的复杂性和数据量自动扩展计算资源。
- 安全性:与 AWS IAM 集成,提供精细的访问控制。支持 S3 存储桶策略、VPC 端点等,以确保数据安全和网络隔离。查询结果可以加密存储在 S3 中。
Amazon Athena 的工作原理
- 数据存储在 Amazon S3: 您的原始数据(例如,日志文件、CSV 文件、JSON 文件等)存储在 Amazon S3 存储桶中。为了优化性能和成本,通常建议将数据转换为列式存储格式(如 Parquet 或 ORC)并进行分区。
- 定义表模式 (Schema):您需要为 S3 中的数据定义一个表模式。这可以通过以下方式完成:AWS Glue Crawler: 使用 Glue Crawler 自动扫描 S3 中的数据,并推断出数据的模式,然后将其存储在 Glue Data Catalog 中。手动创建表: 在 Athena 中使用 DDL (Data Definition Language) 语句手动创建表,指定数据的格式、分隔符和列定义。定义的表模式存储在 AWS Glue Data Catalog 中。
- 编写和执行 SQL 查询:您在 Athena 控制台、AWS CLI 或通过 JDBC/ODBC 驱动程序连接的客户端工具中编写标准 SQL 查询。查询针对您在 Glue Data Catalog 中定义的表执行。
- Athena 执行查询:当您执行查询时,Athena 会解析 SQL 语句,并使用 Glue Data Catalog 中的元数据来理解数据的结构和位置。Athena 会并行地扫描 S3 中相关的数据,只读取查询所需的数据列和分区。查询结果会临时存储在 S3 中,然后返回给用户。
- 按查询付费: 您只需为 Athena 扫描的数据量付费。例如,如果一个查询扫描了 100 GB 的数据,即使最终结果只有几 MB,您仍然需要为扫描的 100 GB 数据付费。因此,优化查询、使用分区和列式存储格式可以显著降低成本。
Amazon Athena 的典型用例
- 数据湖分析: 作为数据湖(存储在 S3 中)的主要查询引擎,用于对原始数据进行探索性分析、即席查询和数据准备。
- 日志分析: 分析 Web 服务器日志、应用程序日志、CloudTrail 日志、VPC 流日志等,以获取运营洞察、排查问题或进行安全审计。
- Ad-hoc 查询: 快速对大规模数据集进行一次性或不频繁的查询,而无需设置和维护复杂的数据仓库。
- 业务智能 (BI) 和报告: 与 Amazon QuickSight 等 BI 工具集成,为业务用户提供交互式仪表板和报告。
- 大数据 ETL (Extract, Transform, Load) 的一部分: 作为 ETL 管道中的转换步骤,对 S3 中的数据进行清洗、转换和聚合,然后加载到其他数据存储中。
- 安全分析: 分析安全日志和事件,识别潜在的威胁和异常行为。
- 数据探索和原型设计: 快速验证数据假设,探索新的数据集,并为更复杂的数据管道进行原型设计。
总结来说,Amazon Athena 是一项强大且灵活的无服务器查询服务,它通过允许您使用标准 SQL 直接查询 Amazon S3 中的数据,极大地简化了大规模数据的分析工作,并以其按查询付费的模式提供了极高的成本效益。
过去考试题
データ分析会社がAmazon Simple Storage Service(Amazon S3)にデータを保存し、最小の労力でこのデータに対してSQLベースの分析を行いたいと考えています。クラウドプラクティショナーとして、このユースケースに対してどのAWSサービスを提案しますか?
- Amazon Athena
- Amazon DynamoDB
- Amazon Aurora
- Amazon Redshift
Amazon Athenaは、Amazon S3に保存されたデータに対してSQLベースのクエリを実行するためのサービスです。
サーバレスであり、設定や管理が不要で、クエリが実行されたときのみ課金されます。
したがって、
最小の労力でS3のデータに対してSQLベースの分析を行いたい場合には、Amazon Athenaが最適な選択となります。
关注
收藏
赞
踩