

【AWS】什么是Amazon S3 Intelligent-Tiering (S3 智能分层)
Amazon S3 Intelligent-Tiering (S3 智能分层) 是一种 Amazon S3 存储类,旨在通过自动将数据移动到最具成本效益的访问层来优化存储成本,而不会影响性能或产生运营开销。
您可以将 S3 Intelligent-Tiering 想象成一个**“智能存储管家”。它特别适用于那些访问模式未知、不断变化或不可预测的数据**。通过每月支付少量的对象监控和自动化费用,S3 Intelligent-Tiering 会监控您的数据访问模式,并自动将对象移动到适当的访问层,从而帮助您节省存储成本。
S3 Intelligent-Tiering 的核心功能和优势
S3 Intelligent-Tiering 提供了一种简单有效的方式来管理存储成本,同时保持数据的高可用性和性能。
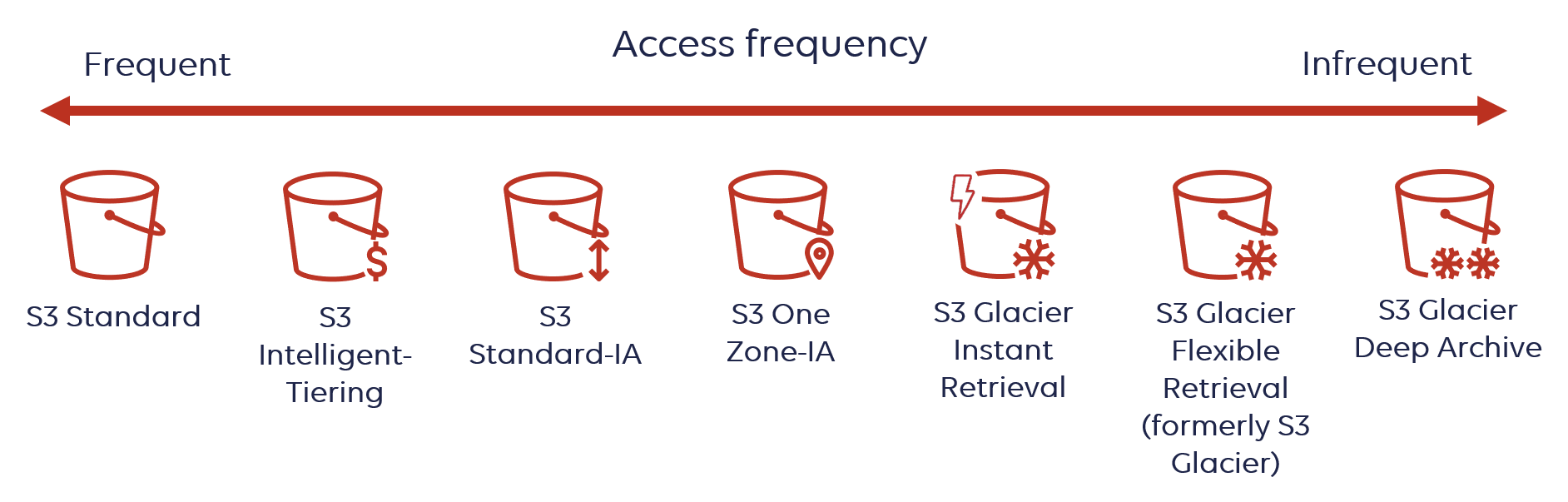
- 自动成本优化:无需手动管理: S3 Intelligent-Tiering 会自动监控对象的访问模式,并将未访问的对象移动到成本较低的访问层,无需您手动设置生命周期策略或进行数据迁移。多层级优化:频繁访问层 (Frequent Access Tier): 适用于经常访问的数据,提供毫秒级延迟和高吞吐量性能。不频繁访问层 (Infrequent Access Tier - IA): 如果对象在 30 天内未被访问,它会自动移动到此层,可节省高达 40% 的存储成本。归档即时访问层 (Archive Instant Access Tier): 如果对象在 90 天内未被访问,它会自动移动到此层,可节省高达 68% 的存储成本。此层仍提供毫秒级访问。可选的异步归档层 (Optional Asynchronous Archive Access Tiers):归档访问层 (Archive Access Tier): 适用于很少访问的数据,检索时间为几分钟到几小时。深度归档访问层 (Deep Archive Access Tier): 适用于极少访问的数据,检索时间为几小时。无检索费用: 从不频繁访问层或归档即时访问层中检索对象时,S3 Intelligent-Tiering 不收取检索费用。如果对象被访问,它会自动移回频繁访问层。无额外分层费用: 在 S3 Intelligent-Tiering 存储类内的访问层之间移动对象时,不会产生额外的分层费用。
- 高性能和持久性:无论数据位于哪个访问层,频繁访问层、不频繁访问层和归档即时访问层都提供与 S3 Standard 相同的低延迟和高吞吐量性能。S3 Intelligent-Tiering 旨在提供 99.999999999% (11 个 9) 的对象持久性。
- 简化运营:消除了管理存储生命周期和手动优化成本的运营开销,让您可以专注于应用程序开发,而不是存储管理。
- 适用于未知访问模式的数据:它是针对访问模式未知、不断变化或不可预测的数据推荐的存储类别,与对象大小或保留期长短无关。例如,数据湖、数据分析和新应用程序的数据。
S3 Intelligent-Tiering 的工作原理
- 上传对象: 您将对象上传到 S3 Intelligent-Tiering 存储类。所有新上传的对象都会自动存储在频繁访问层。
- 监控访问模式: S3 Intelligent-Tiering 会持续监控每个对象的访问模式。
- 自动分层:如果对象在 30 天内未被访问,S3 Intelligent-Tiering 会自动将其移动到不频繁访问层。如果对象在 90 天内未被访问,它会进一步自动移动到归档即时访问层。可选的归档层: 您可以选择激活异步归档功能。如果对象在归档即时访问层中超过 90 天未被访问,它将自动移动到归档访问层。如果对象在归档访问层中超过 180 天未被访问,它将自动移动到深度归档访问层。
- 重新激活: 如果不频繁访问层或归档即时访问层中的对象被访问,它会自动移回频繁访问层,而不会产生任何检索费用或分层费用。
- 小对象处理: 小于 128KB 的对象可以存储在 S3 Intelligent-Tiering 中,但它们不符合自动分层的条件,将始终按频繁访问层的费率收费,且不产生监控和自动化费用。
S3 Intelligent-Tiering 的典型用例
- 数据湖: 存储大量原始数据,这些数据的访问模式可能随时间变化,例如用于大数据分析和机器学习的数据。
- 新应用程序数据: 适用于新开发的应用程序,其数据访问模式尚未确定或可能随用户行为而变化。
- 用户生成内容: 存储用户上传的图片、视频、文档等,这些内容的访问频率可能从高到低波动。
- 日志数据: 收集和存储日志文件,这些文件可能在短期内被频繁访问进行分析,但随后访问频率会降低。
- 备份和灾难恢复: 存储备份数据,这些数据在正常情况下访问频率低,但在需要恢复时需要快速访问。
总结来说,Amazon S3 Intelligent-Tiering 是一种智能且经济高效的存储类,它通过自动化数据分层,帮助您在访问模式不确定的情况下,最大程度地优化存储成本,同时确保数据的高可用性和性能。
过去考试题
ある大規模企業が、複数の事業部門にまたがるデータを統合し、Amazon S3をベースとしたデータレイクを構築しようとしています。このプロジェクトの総所有コスト(TCO)を最小限に抑えるために、最も重要な検討事項は何でしょうか?
- S3ライフサイクルポリシーの実装とインテリジェント階層化の活用
- データの圧縮と重複排除技術の適用
- クロスリージョンレプリケーションの設定
- S3バケットの暗号化とアクセス制御の最適化
正解はAです。S3ライフサイクルポリシーの実装とインテリジェント階層化の活用が、長期的なTCOを最小限に抑える上で最も重要です。これにより、データのアクセス頻度に基づいて自動的に最適なストレージクラスにデータを移動させ、コストを大幅に削減できます。また、AIを活用したインテリジェント階層化により、データ使用パターンを分析し、最適なストレージクラスを動的に選択することができます。
選択肢B:データの圧縮と重複排除はストレージ使用量を減らすのに効果的ですが、処理オーバーヘッドが発生し、すべてのデータタイプに適用できるわけではありません。TCOへの影響は限定的です。
選択肢C:クロスリージョンレプリケーションは災害復旧や地理的冗長性のために重要ですが、追加のストレージコストとデータ転送料金が発生するため、TCOを増加させる可能性があります。
選択肢D:S3バケットの暗号化とアクセス制御は重要なセキュリティ対策ですが、直接的なコスト削減効果は限られています。ただし、データ漏洩のリスクを軽減することで間接的にTCOに影響を与える可能性があります。