
【AWS】什么是AWS Glue

【AWS】什么是AWS?Glue
AWS Glue 是一项完全托管的无服务器数据集成服务。它旨在让分析用户、数据工程师和开发人员能够轻松地发现、准备、组合和移动数据,以便进行分析、机器学习和应用程序开发。
您可以将 AWS Glue 想象成一个**“智能数据工厂”**,它自动化了传统上复杂且耗时的提取、转换和加载 (ETL) 过程。它消除了您自行构建和维护数据集成基础设施的复杂性,让您可以专注于从数据中获取价值。
AWS Glue 的核心功能和优势
AWS Glue 提供了一套全面的功能,以简化数据集成工作流程:
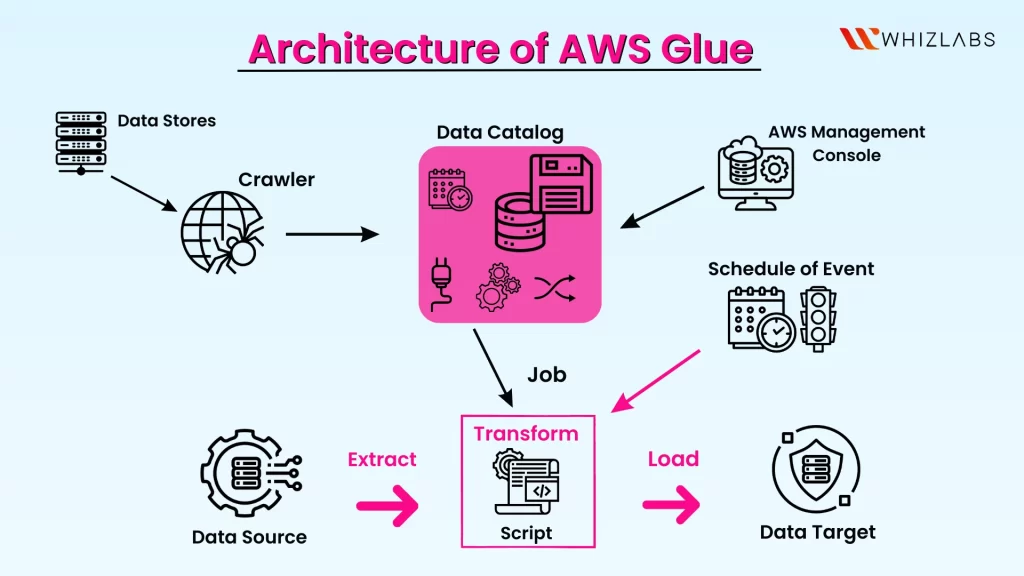
- 统一的元数据目录 (AWS Glue Data Catalog):数据发现: Glue 的“爬网程序 (Crawlers)”可以自动连接到您的数据源(如 Amazon S3、RDS、DynamoDB 等),识别数据格式和模式,并推断出表结构。集中式存储: 将所有数据资产的元数据(表定义、物理位置、业务相关属性等)存储在一个持久的、集中式的存储库中。跨服务集成: Data Catalog 可以被其他 AWS 分析和机器学习服务(如 Amazon Athena、Amazon Redshift Spectrum、Amazon EMR、Amazon SageMaker)无缝使用,提供统一的数据视图。
- 无服务器 ETL 引擎:按需计算: Glue 提供了一个完全托管的、无服务器的 Apache Spark 或 Python 环境来运行 ETL 作业。您无需预置、配置或管理任何服务器。自动扩展: 根据数据处理需求自动扩展计算资源,从 GB 级到 PB 级的数据都能高效处理。智能代码生成: Glue 可以自动生成用于提取、转换和加载数据的 ETL 脚本(Python 或 Scala),大大简化了作业开发。您也可以自定义这些脚本。多种处理模式: 支持批处理、微批处理和流式 ETL 作业。
- 数据质量和治理:数据质量规则: 允许您定义和强制执行数据质量规则,以确保数据的准确性和一致性。模式注册表 (Schema Registry): 帮助管理数据流的模式演变,确保数据生产者和消费者之间的兼容性。
- 简化操作和管理:内置调度和监控: Glue 作业可以按计划、按需或基于事件进行调用。它提供灵活的调度程序、作业监控和警报功能。容错和重试: Glue 会处理所有的作业间依赖关系、过滤不良数据,并在作业失败时进行重试。降低操作复杂性: 消除了基础设施管理,让团队能够专注于构建数据工作流,而不是维护服务器。
- 成本效益:按使用量付费: 您只需为 ETL 作业运行时实际消耗的计算资源付费,没有最低费用。无需基础设施维护: 节省了购买、设置和管理服务器的成本。
- 生成式 AI 辅助:提供智能代码生成、AI 辅助的 Spark 升级和内置的 Spark 故障排除,在整个数据集成过程中提供 AI 驱动的帮助。
AWS Glue 的工作原理
AWS Glue 的核心在于其三个主要组件协同工作:
- AWS Glue Data Catalog (数据目录):它是您的持久性元数据存储。爬网程序 (Crawlers): 您配置爬网程序连接到您的数据源(如 S3 存储桶、RDS 数据库、DynamoDB 表),它会自动扫描数据,推断出数据模式,并将表定义、分区信息、数据位置等元数据写入 Data Catalog。分类器 (Classifiers): 爬网程序使用分类器来确定数据格式和模式。您可以创建自定义分类器来处理非标准数据格式。
- AWS Glue ETL 作业 (ETL Jobs):脚本生成: 基于 Data Catalog 中的元数据,Glue 可以自动生成用于数据转换的 Apache Spark 或 Python 脚本。开发环境: 您可以在 Glue Studio(可视化 ETL 开发界面)、Glue 交互式会话(无服务器笔记本)或您选择的 IDE 中编辑、调试和测试这些脚本。作业运行: 当您运行 Glue 作业时,Glue 会自动预置、配置和扩展所需的计算资源来执行脚本,处理数据转换和加载。
- AWS Glue 触发器和调度器 (Triggers and Schedulers):触发器: 您可以设置触发器来启动 Glue 作业,可以是按计划(例如,每日、每小时)、按需,或基于事件(例如,当新文件上传到 S3 时)。调度器: Glue 提供一个灵活的调度程序来管理作业的执行,包括处理作业间的依赖关系。
AWS Glue 的典型用例
- 构建数据湖: 作为数据湖的核心组件,用于将来自各种来源的原始数据摄取、清洗、转换并加载到 Amazon S3 数据湖中。
- ETL 管道: 构建和自动化复杂的 ETL 管道,用于数据仓库(如 Amazon Redshift)或数据湖的填充。
- 数据准备用于分析和机器学习: 清洗、规范化、合并和丰富数据,使其适合进行商业智能 (BI) 报告、数据分析和机器学习模型训练。
- 流式 ETL: 处理实时数据流,进行连续的数据转换和分析。
- 数据目录和治理: 为整个组织提供统一的数据元数据视图,并实施数据治理策略。
- 数据迁移和同步: 在不同数据存储之间(包括本地和云端)进行数据迁移和同步。
总结来说,AWS Glue 是一项功能强大、无服务器且高度可扩展的数据集成服务,它通过自动化数据发现、ETL 作业生成和执行,以及提供统一的元数据目录,极大地简化了数据准备和组合的复杂性,帮助企业更快地从数据中获取洞察。
过去考试题
分析のためのデータを準備するために使用できるAWSのサーバーレスサービスはどれですか?
- Amazon Athena
- Amazon Redshift
- Amazon EMR
- AWS Glue
AWS Glueは、データの準備とロードを自動化する完全に管理されたETL(Extract, Transform, Load)サービスです。
サーバーレスであるため、インフラストラクチャの管理が不要です。
他の選択肢であるAmazon Athenaはサーバーレスのクエリサービス、
Amazon Redshiftはデータウェアハウスサービス、
Amazon EMRはビッグデータフレームワークを実行するためのサービスであり、データの準備には直接使用されません。
关注
收藏
赞
踩