
【AWS】什么是AWS Data Pipeline

【AWS】什么是AWS Data Pipeline
AWS Data Pipeline 是一项 Web 服务,用于自动化数据的移动和转换。它允许您定义数据驱动型工作流,以便任务可以依赖于先前任务的成功完成。
您可以将 AWS Data Pipeline 想象成一个**“数据流的调度器和协调器”**。它帮助您定期访问存储数据的位置,对数据进行大规模转换和处理,并将结果高效地传输到其他 AWS 服务或本地数据源。
重要提示: AWS Data Pipeline 服务目前处于维护模式,没有计划新的功能或区域扩展。AWS 建议将现有工作负载迁移到其他更现代的替代服务,如 AWS Glue (用于 ETL 和数据集成)、AWS Step Functions (用于协调 AWS 服务组件) 或 Amazon Managed Workflows for Apache Airflow (Amazon MWAA) (用于管理 Apache Airflow 工作流协调)。
AWS Data Pipeline 的核心功能和优势 (历史和当前用途)
尽管处于维护模式,了解其核心功能有助于理解其设计目的:
- 自动化数据工作流:允许您定义复杂的数据处理工作负载,这些工作负载可以具有容错性、可重复性和高可用性。任务可以根据预设的计划(例如,每日、每周)或依赖于先前任务的成功完成而自动执行。
- 数据移动和转换:支持在不同的 AWS 计算、存储服务(如 Amazon S3、Amazon EMR、Amazon Redshift)以及本地数据源之间移动和转换数据。可以执行数据提取 (Extract)、转换 (Transform) 和加载 (Load) (ETL) 操作。
- 任务间依赖管理:能够确保资源可用性并有效管理任务之间的依赖关系,即使在上传日志时发生不可预见的延迟,也能确保后续任务等待数据准备就绪。
- 故障处理和通知:可以创建故障通知系统或自动重试瞬态故障,提高数据管道的健壮性。
- 与 AWS 服务集成:与 Amazon S3、Amazon EMR、Amazon RDS、Amazon Redshift 等 AWS 服务集成,方便构建端到端的数据处理解决方案。
AWS Data Pipeline 的工作原理 (简要)
- 管道定义 (Pipeline Definition): 您使用 JSON 文件定义数据管理的业务逻辑,包括数据源、活动(要执行的工作)、计划、资源(运行活动的计算资源,如 EC2 实例或 EMR 集群)和先决条件。
- 管道 (Pipeline): 您将管道定义上传到 Data Pipeline 服务并激活它。管道会根据定义调度和执行任务,必要时创建和管理底层计算资源。
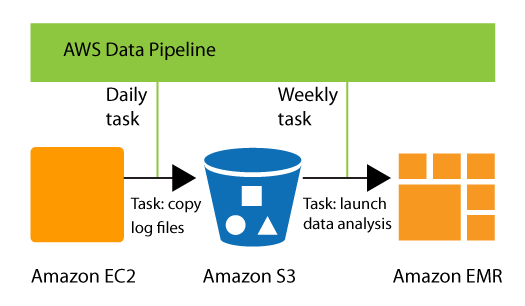
- 任务执行器 (Task Runner): 这是一个在管道定义创建的资源上自动运行的应用程序,它轮询任务并执行它们,例如将日志文件复制到 Amazon S3 或启动 Amazon EMR 集群。
典型用例 (历史用途,现推荐迁移)
- 日志处理: 定期从服务器收集日志文件,将其移动到 S3,然后启动 EMR 集群进行分析。
- 数据仓库 ETL: 将数据从各种源提取、转换并加载到数据仓库(如 Amazon Redshift)。
- 数据库备份和复制: 定期将数据库备份到 S3。
- 跨区域数据传输: 自动化在不同 AWS 区域之间的数据传输。
总结来说,AWS Data Pipeline 曾是一项用于自动化数据移动和转换的 Web 服务,通过定义数据驱动型工作流来协调任务。然而,它目前处于维护模式,建议使用 AWS Glue、AWS Step Functions 或 Amazon MWAA 等更现代的 AWS 服务来替代其功能。
关注
收藏
赞
踩