

【AWS】什么是Amazon EMR
Amazon EMR(以前称为 Amazon Elastic MapReduce)是一个托管集群平台,可简化大数据框架(例如 Apache Hadoop 和 Apache Spark)的运行,以处理和分析大量数据。它允许您使用这些框架和相关的开源项目,处理用于分析目的的数据和业务智能工作负载。
您可以将 Amazon EMR 想象成一个**“云中的大数据处理工厂”**。它消除了构建、管理和扩展大数据集群的复杂性,让您可以专注于从数据中获取洞察,而不是管理基础设施。
Amazon EMR 的核心功能和优势
EMR 的设计目标是让大数据处理变得简单、弹性且经济高效。
- 简化大数据框架的运行:托管服务: EMR 完全托管了大数据集群的部署、配置、修补、监控和维护。您无需担心底层 EC2 实例、操作系统或大数据软件的安装和管理。支持多种开源框架: EMR 支持广泛的流行大数据框架和应用程序,包括:Apache Spark: 用于快速大规模数据处理、机器学习和实时分析。Apache Hadoop: 用于分布式存储和处理大型数据集。Presto/Trino: 用于交互式 SQL 查询。Apache Hive: 数据仓库工具,提供 SQL 接口。Apache HBase: 分布式、可伸缩的非关系型数据库。Apache Flink: 用于流处理和批处理。Apache Zeppelin/JupyterHub: 用于交互式数据分析和协作。EMR Studio: 提供基于 Web 的集成开发环境 (IDE),用于轻松开发、可视化和调试使用 R、Python、Scala 和 PySpark 编写的数据工程和数据科学应用程序。
- 弹性伸缩:按需容量: 您可以快速预置一个、数百个甚至数千个计算实例或容器,以处理任意规模的数据。自动扩展: EMR 支持托管式扩展,可以根据工作负载需求自动增加或减少集群中的实例数量,确保资源利用率最优化,并避免为空闲容量付费。灵活的实例类型: 支持多种 Amazon EC2 实例类型,包括按需实例、预留实例 (RI) 和竞价型实例 (Spot Instances),以优化成本。
- 成本效益:按秒计费: EMR 的定价基于您使用的 EC2 实例类型和数量,按秒计费(至少一分钟),这有助于精确控制成本。竞价型实例集成: 可以利用价格更低的竞价型实例来运行任务节点,显著降低成本。与 S3 集成: EMR 可以直接处理存储在 Amazon S3 中的数据(通过 EMRFS),从而将计算与存储分离,进一步优化成本和弹性。
- 高可用性和可靠性:EMR 集群设计为高可用性,可持续监控集群的运行状况,重试失败的任务,并自动更换性能不佳或出现故障的实例。主节点故障时可以自动进行故障转移。
- 安全性:支持传输中和静态数据加密。与 AWS IAM 集成,可以精细控制对集群和数据的访问权限。可以与 Amazon Lake Formation 或 Apache Ranger 集成,对数据库、表和列应用精细数据访问控制。
Amazon EMR 的工作原理
Amazon EMR 集群由 Amazon EC2 实例组成,这些实例具有不同的角色:
- 主节点 (Master Node):管理集群,协调数据和任务在其他节点之间的分配。跟踪任务状态并监控集群的运行状况。每个集群有一个主节点。
- 核心节点 (Core Nodes):运行任务并将数据存储在 Hadoop 分布式文件系统 (HDFS) 中(如果使用 HDFS)。多节点集群至少有一个核心节点。
- 任务节点 (Task Nodes):仅运行任务,不存储数据在 HDFS 中(可选)。任务节点通常用于扩展集群的计算能力,并且是使用竞价型实例的理想选择,因为它们不存储持久数据。
工作流程:
- 创建集群: 您在 EMR 控制台或通过 API 指定要使用的框架(如 Spark、Hadoop)、实例类型和数量。
- 数据输入: 通常,数据会存储在 Amazon S3 中。EMRFS (EMR File System) 允许 EMR 集群直接访问 S3 中的数据,就像访问本地文件系统一样。
- 任务提交: 您将大数据处理任务(例如 Spark 作业、Hive 查询)提交到 EMR 集群。
- 分布式处理: 主节点将任务分配给核心节点和任务节点。这些节点并行处理数据,并将中间结果存储在 HDFS 或 S3 中。
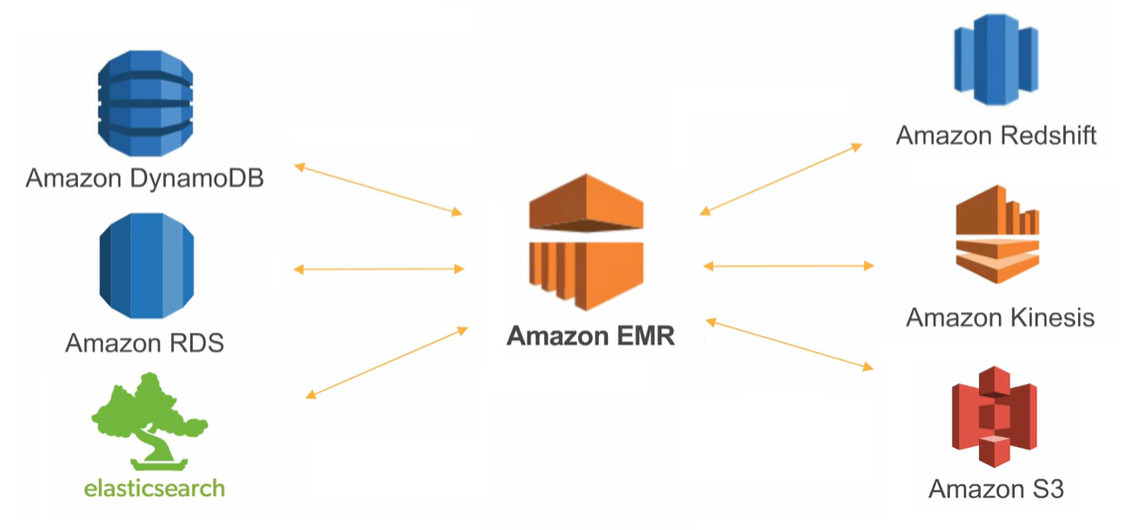
- 结果输出: 处理完成后,结果可以存储回 Amazon S3、Amazon Redshift、Amazon DynamoDB 或其他数据存储中。
- 集群终止: 任务完成后,您可以终止集群,从而停止计费并避免空闲资源浪费。
Amazon EMR 的典型用例
- 大数据处理和 ETL (Extract, Transform, Load): 处理大量原始数据,进行数据清洗、转换和加载到数据仓库或数据湖中。
- 日志分析: 分析 Web 服务器日志、应用程序日志和其他机器生成的数据,以获取运营洞察。
- Web 索引和搜索: 构建和维护大规模的 Web 索引。
- 机器学习: 使用 Spark MLlib 等框架进行大规模机器学习模型的训练和部署。
- 实时流数据处理: 结合 Amazon Kinesis 等服务,对实时流数据进行处理和分析。
- 交互式分析: 使用 Presto/Trino 或 Hive 对存储在 S3 或其他数据存储中的数据进行交互式查询。
- 基因组学和科学模拟: 处理和分析大规模的科学数据集。
- 财务分析: 进行复杂的财务数据分析和建模。
总结来说,Amazon EMR 是一项强大的托管式大数据服务,它通过简化流行开源框架的运行、提供弹性伸缩和成本优化功能,帮助企业轻松、高效地处理和分析大规模数据集,从而加速数据驱动的决策和创新。
过去考试题
クラウド上で大規模なデータ処理と分析を実行するために、Apache HadoopやApache Sparkなどのオープンソースフレームワークを使用したいと考えています。AWSのどのサービスを利用するのが最も適切ですか?
- Amazon RDS
- Amazon EMR
- Amazon Redshift
- AWS Glue
Amazon EMRは、クラウド上で大規模なデータ処理と分析を実行するために最適化されたサービスです。
Apache Hadoop、Apache Spark、Apache HBase、Apache Flinkなどのオープンソースフレームワークを使用して、ペタバイト規模のデータを迅速に処理できます。
以下は各選択肢についての詳細な解説です。
Amazon RDS(Relational Database Service)は、クラウド上でリレーショナルデータベースを簡単にセットアップ、運用、スケーリングするためのサービスです。主にMySQL、PostgreSQL、MariaDB、Oracle、Microsoft SQL Serverなどのデータベースエンジンをサポートしています。Amazon RDSはリレーショナルデータベースに適していますが、大規模なデータ処理や分析には適していません。
Amazon Redshiftは、ペタバイト規模のデータウェアハウスサービスで、高速なクエリ処理能力を持っています。データウェアハウジングとビジネスインテリジェンスに特化していますが、Apache HadoopやApache Sparkなどのオープンソースフレームワークを使用した大規模データ処理には特化していません。
AWS Glueは、データのETL(抽出、変換、ロード)作業を自動化するためのサービスです。データの準備と統合を簡単に行うために使用されます。Apache Sparkを使用してデータ処理を行うことができますが、Amazon EMRのような包括的な大規模データ処理フレームワークのセットアップと管理には適していません。