

【AWS】什么是Amazon Aurora Global Database
Amazon Aurora Global Database 是一项专为全球分布式应用程序设计的 Amazon Aurora 功能。
它允许单个 Amazon Aurora 数据库跨越多个 AWS 区域,从而在不影响数据库性能的情况下实现数据复制,在每个区域提供低延迟的快速本地读取,并在发生区域级中断时提供强大的灾难恢复能力。
你可以把 Aurora Global Database 想象成一个“全球同步的数据库集群”,它在多个地理位置分散的 AWS 区域之间保持数据的高度一致性,同时优化了全球用户的访问体验。
只有主集群才能执行写入操作。
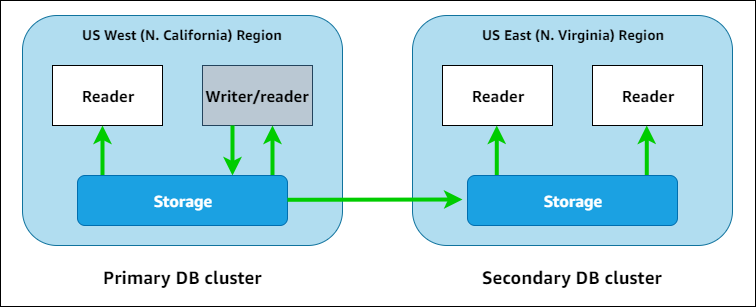
Amazon Aurora Global Database 的核心特点和优势
Aurora Global Database 旨在解决全球性应用程序在数据库层面遇到的挑战,例如跨区域延迟、灾难恢复和全球读写扩展性。
跨区域数据复制(基于存储):
Aurora Global Database 使用 Aurora 存储层中的专用基础设施进行异步数据复制。这意味着数据复制发生在存储层,不会占用数据库实例的计算资源,因此对数据库性能的影响极小。
典型的跨区域复制延迟通常低于 1 秒,实现了近乎实时的全球数据同步。
全球低延迟读取:
在每个辅助区域(Secondary Region)中,你可以部署只读副本。全球用户可以连接到离他们最近的区域中的只读副本,从而获得低延迟的本地读取体验。
每个辅助区域可以支持多达 16 个只读数据库实例,进一步提高读取可扩展性。
强大的灾难恢复 (Disaster Recovery, DR) 能力:
如果主区域(Primary Region)发生性能下降或中断,你可以将其中一个辅助区域在不到 1 分钟内提升为具有读/写功能的主区域。
这为你的应用程序提供了1 秒的有效恢复点目标 (RPO) 和不到 1 分钟的恢复时间目标 (RTO)。这意味着在发生区域级灾难时,你最多只会丢失 1 秒的数据,并且能在 1 分钟内恢复业务运营。
支持受控切换 (Switchover),用于计划内的事件,如灾难恢复演练或区域轮换。
内置容错功能:
由于数据库实例不依赖于单个 AWS 区域,而是依赖于多个区域和不同的可用区,因此它提供了内置的容错功能。
写入转发 (Write Forwarding) (部分引擎支持):
对于某些 Aurora 引擎(如 Aurora PostgreSQL),辅助区域的只读副本可以支持写入转发功能,将写入操作透明地转发到主区域。这在某些场景下可以简化应用程序架构,但需要注意写入操作的实际延迟仍然取决于主区域的距离。
灵活的配置和定价:
你可以为主区域和辅助区域中的数据库集群选择不同的配置选项,例如,主区域配置为 Amazon Aurora I/O-Optimized,辅助区域配置为 Aurora Standard,反之亦然,以优化成本。
兼容性:
Amazon Aurora Global Database 支持与 MySQL 兼容的 Amazon Aurora 和与 PostgreSQL 兼容的 Amazon Aurora。
Amazon Aurora Global Database 的典型用例
Aurora Global Database 非常适合需要全球范围内的低延迟访问和强大灾难恢复能力的应用程序:
全球分布式应用程序:
社交媒体平台、在线游戏、视频流服务等,其用户遍布全球,需要从离他们最近的地点获得快速的数据库访问。
全球电子商务平台:
确保全球客户都能获得一致且快速的购物体验,并能在区域性故障时保持业务连续性。
企业级灾难恢复:
对于对数据可用性和业务连续性有极高要求的关键业务应用程序,Aurora Global Database 提供了强大的跨区域灾难恢复策略,远超单区域的多可用区部署。
数据分析和报告:
允许全球团队在各自区域内对数据进行低延迟的读取和分析,而无需担心跨区域数据传输的延迟。
“跟随太阳”运营模式:
对于需要 24/7 全天候运营且在不同时区有团队协作的业务,可以通过在不同区域之间切换主区域来优化性能和管理。
总结
Amazon Aurora Global Database 是 Amazon Aurora 的一项高级功能,它通过在多个 AWS 区域之间实现高性能、低延迟的数据复制,为全球分布式应用程序提供了卓越的可用性、灾难恢复能力和读取扩展性。 它是构建真正全球化、高弹性数据库解决方案的关键组件。